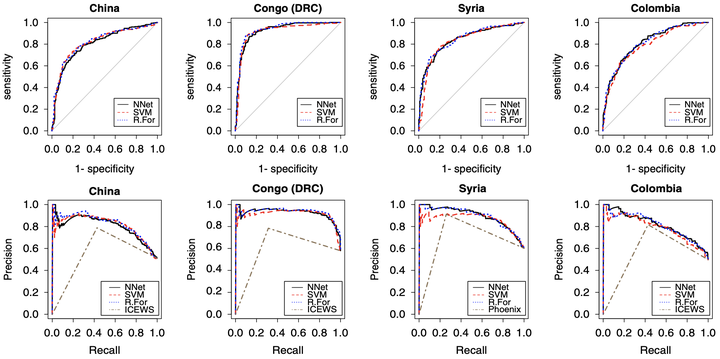
Improving geolocation accuracy in text data has long been a goal of automated text processing. We depart from the conventional method and introduce a two-stage supervised machine-learning algorithm that evaluates each location mention to be either correct or incorrect. We extract contextual information from texts, i.e., N-gram patterns for location words, mention frequency, and the context of sentences containing location words. We then estimate model parameters using a training data set and use this model to predict whether a location word in the test data set accurately represents the location of an event. We demonstrate these steps by constructing customized geolocation event data at the subnational level using news articles collected from around the world. The results show that the proposed algorithm outperforms existing geocoders even in a case added post hoc to test the generality of the developed algorithm.
Howard Liu
Assistant Professor
Department of Political Science
My research interests include state repression, protest, dictatorship, armed conflict, and networks.